Simulating data to check or preregister code
One of the simplest uses of simulations is to make a dataset on which you can run and therefore pre-specify your analytic code.
For example, let’s say you plan to collect an observational dataset and want to look at the effect of smoking on lung cancer. A typical protocol might state that the data will be analysed by logistic regression, adjusting for confounders. But which confounders exactly? How will each variable be coded? What type of logistic regression will you use?
Making a dataset that has the variables you expect your real dataset will have allows you to exactly state (in code rather than potentially ambiguous words) what you will do.
This is really useful if you want input, e.g. from a statistician – they can look at your code and more clearly see what you are trying to do. It has the added benefit of forcing you to really think about what your dataset will look like! I’ve found this to be very useful in the past.
It’s very easy to make a dataset. Let’s take the simple example about smoking and lung cancer. We are interested in only 4 variables:
smoking_status, a binary variable indicating whether an individual smokes (Yes/No).lung_cancer, a binary variable indicating whether an individual has lung cancer (Yes/No).sex, a binary variable indicating an individual’s sex (M/F).age, a numeric variable containing an individual’s age (in years).
Here is the top of the simulated dataset.

YOUR TURN:
Can you recreate it? Try it yourself!
HINT: use the
data.frame(),sample(), andrnorm()functions.Now that you’ve made a dataset, try to run a logistic regression on your data with
lung_canceras the outcome.Do you face any error message? Does the data need to be in a specific format for statistical models to run?
Once we have a working model, we can look at the summary and make sure it behaves as we expected, and we can share the code with collaborators or reviewers.
You could combine this approach with the sampling approaches you learned on the previous two pages to look at power for more complex analyses like this.
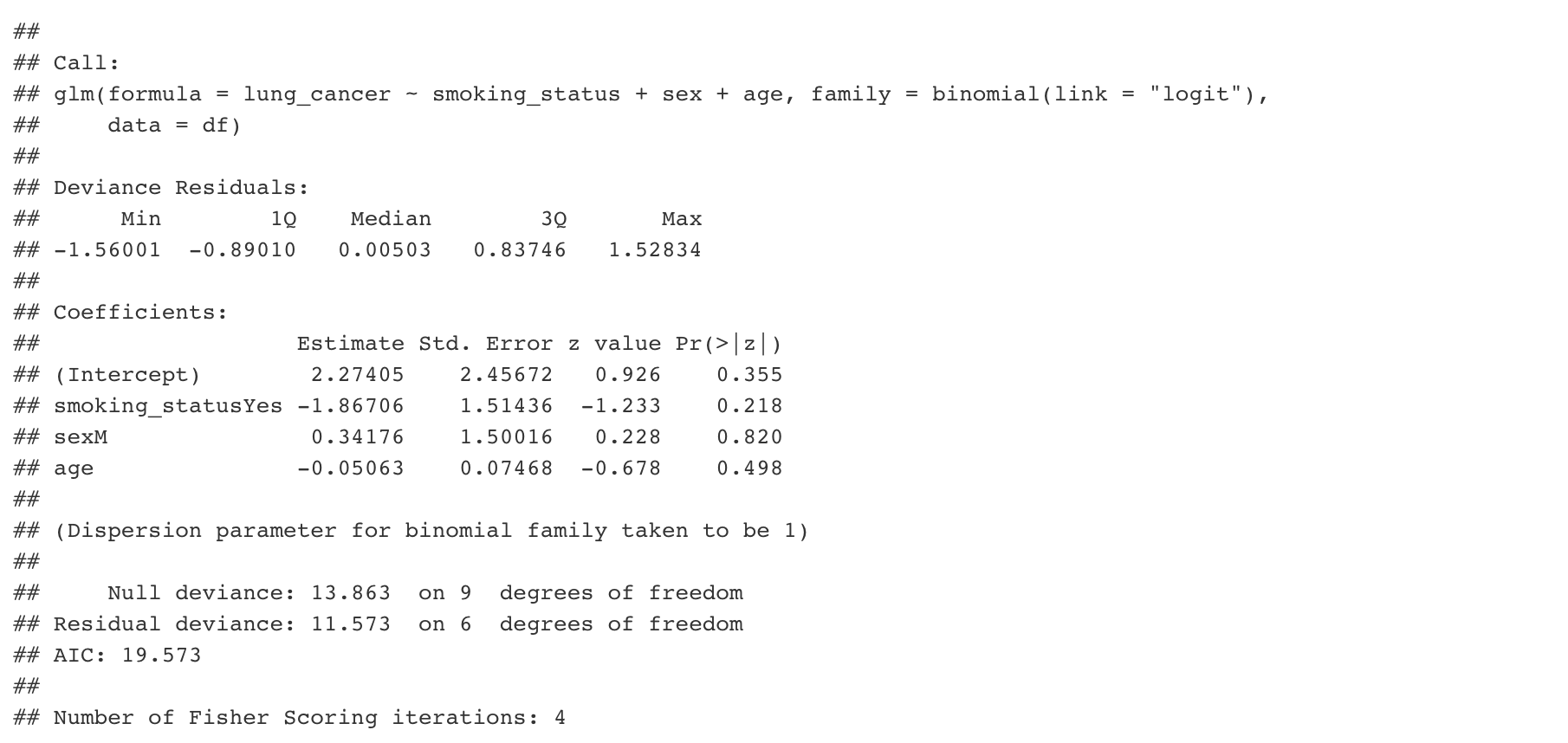
And that’s it! We have written down our code in a way that is totally unambiguous. This practice is useful for any project: you can include the exact code that you plan to use in a preregistration, and reviewers will be able to verify that you did what you planned.
A real example of a simple simulation like this, used in the submission of a registered report, can be found in the R Markdown file here.