After completing this part of the tutorial, you will be able to apply selected perturbative techniques in R.
The core idea behind perturbative techniques is to introduce controlled changes to data values. Unlike non-perturbative techniques that hide or remove information, perturbative methods keep all records and variables in the dataset but alter the values themselves. The key requirement is that the changes should be large enough to prevent re-identification but small enough that the overall statistical properties of the data (means, variances, correlations) are preserved.
In general, perturbation does not increase k-anonymity, since values are not generalized but instead just changed. Recall that k-anonymity counts how many records share the same combination of indirect identifiers. It only goes up when distinct values are collapsed into shared, broader categories, the way recoding or suppression does. Perturbation works differently: it swaps each value for another specific value rather than a broader category, so a record that was unique on its quasi-identifiers stays unique—it just carries different numbers. It may reshuffle which records look unusual, but it does not merge them into the larger shared groups that a higher k requires. On top of that, we typically perturb continuous variables such as income, which are not even part of the categorical key that k-anonymity is calculated on in the first place. Perturbation therefore adds another layer of protection—especially for continuous variables—rather than raising k-anonymity.
In this chapter, I will present a few perturbative techniques introduced in Carvalho et al. (2023).
Examples of Perturbative Techniques
Swapping
Swapping exchanges values of a variable between participants. Instead of altering the values themselves, it breaks the link between a record and the individual it belongs to.
There are two main variants. Record swapping (also known as data swapping) applies to categorical variables: values like gender or country of residence are swapped between records. A useful property here is t-order equivalence. For example, 1-order equivalence means the marginal frequencies are preserved (same number of males and females as before), and 2-order equivalence means joint frequencies are also preserved (same number of males and females from each country).
Record swapping: gender values are exchanged between records. In this case, the 1-order frequencies stay the same, but the 2-order frequencies change, meaning that only 1-order equivalence is reached.
Rank swapping applies to continuous variables: values are only swapped with other values that are close in rank, which limits how much the distribution is distorted.
The main advantage of swapping is that it removes the relationship between a record and the individual without introducing new values that never existed in the data. It can protect rare and unique values and works across variable types. On the downside, non-random swapping requires careful implementation, and swapping can produce unusual combinations of values that did not exist in the original data.
Re-sampling
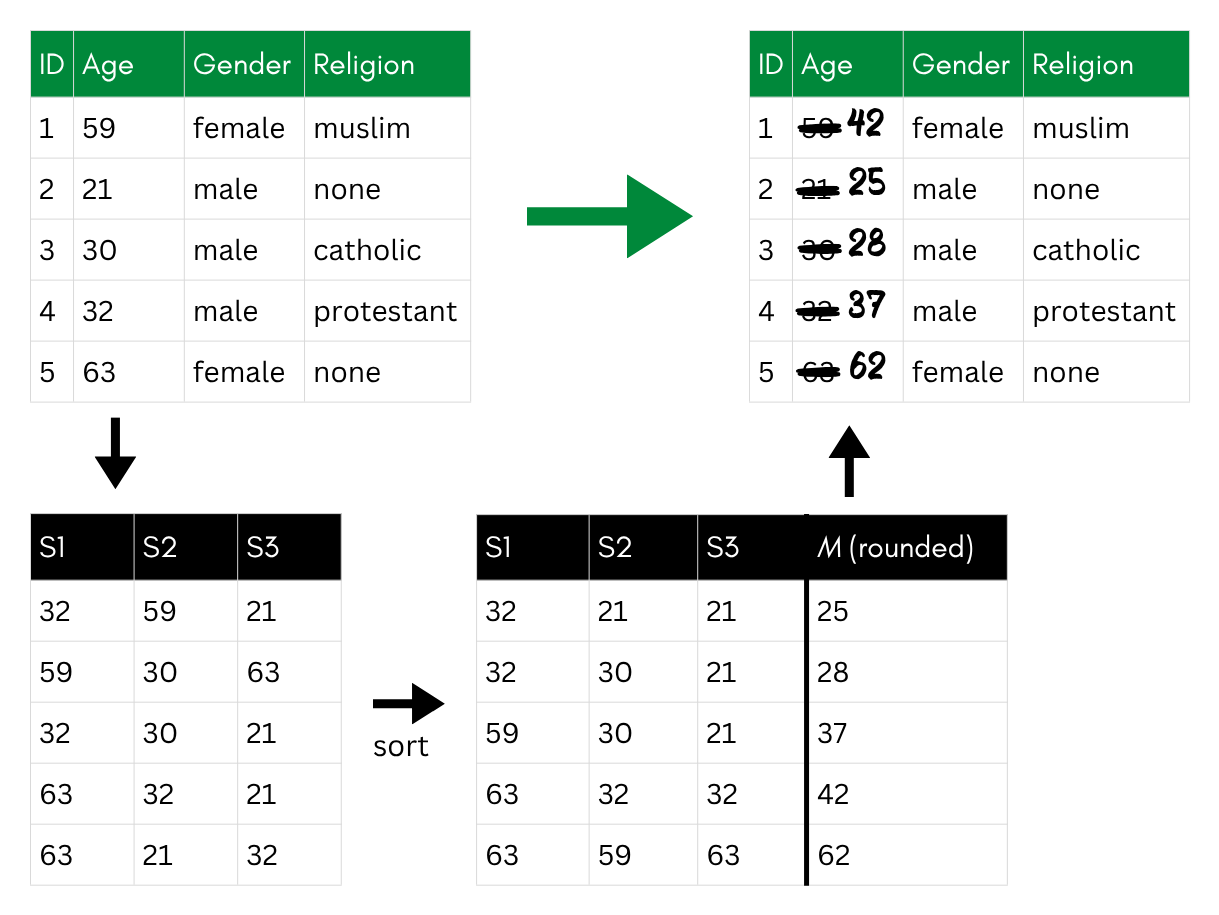
Re-sampling replaces original values with averages computed from bootstrap samples (Hundepool et al. 2026). You draw multiple independent bootstrap samples from the original data with replacement, with the same sample size as your original data, and sort the values within each sample. You then compute the average of the smallest values across all samples, then of the second-smallest ones, and so forth, and replace the corresponding original values (i.e., the smallest original value with the average of the smallest values in the samples, etc.). The result preserves the overall distribution, but individual values no longer correspond to real observations.
Re-sampling: original ages are replaced with averages of sorted values across t = 3 bootstrapped samples.
Noise
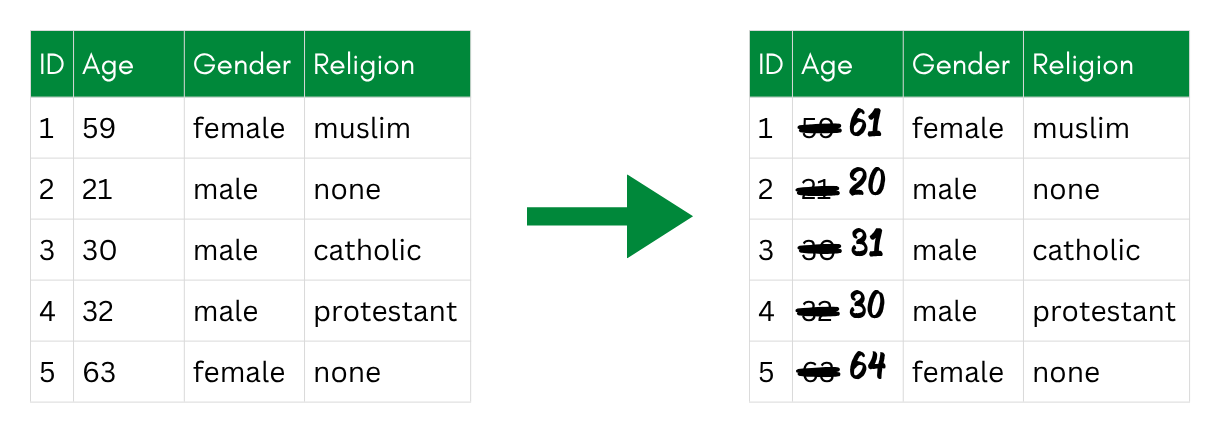
Noise addition (also known as randomization) adds a random value to each original value. The most common form is additive noise: a random draw from a distribution (typically normal with mean 0) is added to the original value. Multiplicative noise works similarly but multiplies the original value by a random factor, which scales the perturbation to the magnitude of the variable.
The noise can be uncorrelated—each value gets an independent random draw—or correlated with the original values, which better preserves the correlation structure between variables. Transformations of the variable (e.g., log-transforming income before adding noise) are also possible and can improve the result for skewed distributions.
Noise addition: a random value is added to each age, so every value changes slightly.
NoteDifferential Privacy
Noise addition leaves one question open: how much noise is enough? In this tutorial, we answer it empirically—add noise, then measure the remaining disclosure risk (as you will do in the exercise below). Differential privacy approaches the same question from the other direction: you first fix a privacy level, and the noise is then calibrated mathematically so that a formal guarantee holds. Importantly, this guarantee applies to an algorithm—the whole procedure of computing a result and adding noise to it—not to a dataset: the algorithm’s output must be essentially the same whether or not any single individual’s data is included, so an attacker learns (almost) nothing about anyone’s participation. One consequence: you cannot look at a dataset and call it “differentially private”; the guarantee belongs to the process that produced an output.
You already know a technique that provides this guarantee: the randomized response technique from the chapter on mechanisms. Because each answer is randomized with known probabilities, a recorded “yes” proves nothing about any single person, yet the true prevalence can still be estimated.
That example also shows a practical difference from an approach like k-anonymity, which requires a trusted party holding the complete dataset to anonymize it. With differential privacy, noise can instead be added locally—in the case of randomized response, by each participant themselves, before their data is even collected.
For R users, the diffpriv package implements differential privacy mechanisms and is a good starting point for exploring this approach (Rubinstein and Alda 2017).
Microaggregation
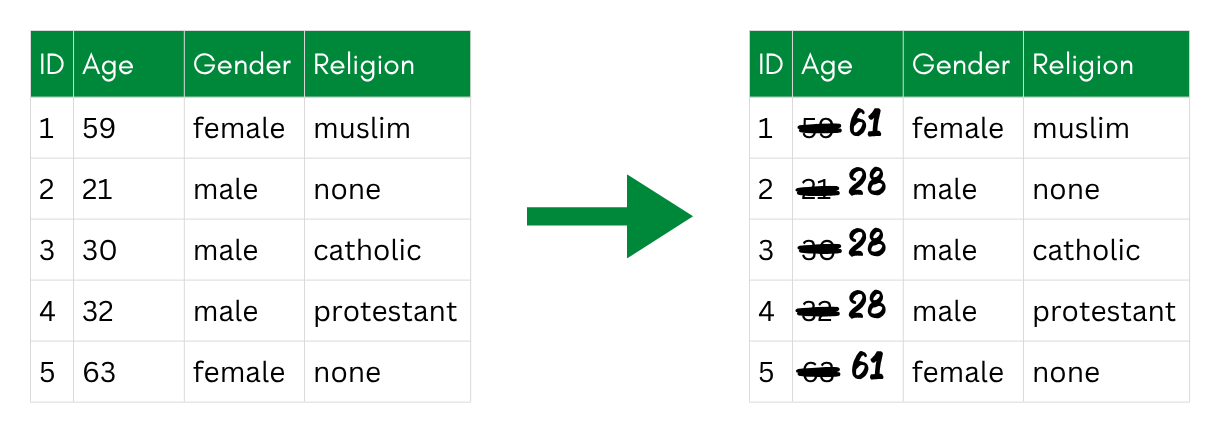
Microaggregation groups records by similarity on the variable of interest and replaces each value with a group aggregate—usually the mean or median. Records within the same group end up sharing the same value, which makes it impossible to single out an individual based on that variable alone.
Microaggregation: records are grouped and each age is replaced with its group’s average, so records share the same value.
The quality of the result depends on how homogeneous the groups are: the more similar the original values within a group, the less information is lost when replacing them with the group mean. This is why the grouping algorithm matters. The default in sdcMicro, mdav (Maximum Distance to Average Vector), tries to form compact groups to minimize distortion.
Rounding
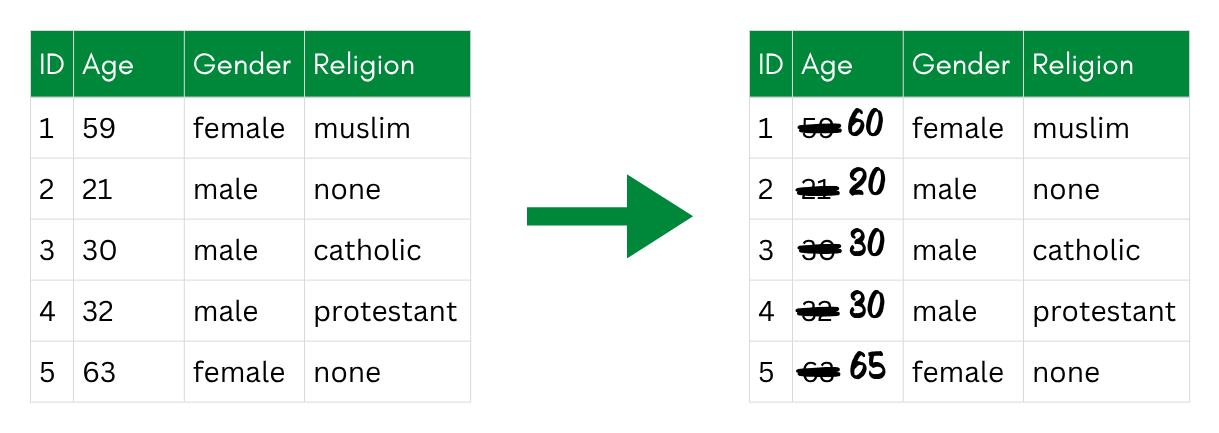
Rounding replaces exact values with rounded versions. For example, one can round income to the nearest €1,000, or age to the nearest 5 years. It is the simplest perturbative technique and is easy to explain and verify. The downside is that it provides relatively weak protection on its own, since the original value can often be guessed within a small range, or looses quite a lot of data in case of larger ranges that are rounded to the same value.
Rounding: exact ages are replaced with rounded values (here to the nearest 10).
PRAM
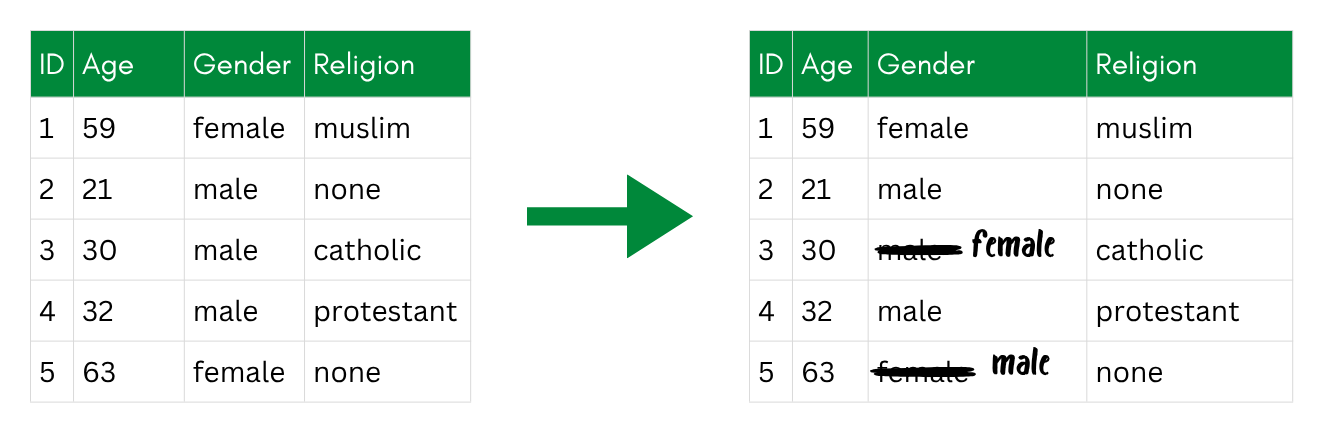
PRAM (Post RAndomisation Method) applies to categorical variables. Each value is randomly recoded to a different category with a certain probability defined in a transition matrix. For example, a participant recorded as “male” might be recoded to “female” with probability 0.05 and kept as “male” with probability 0.95. The transition probabilities are chosen so that the distribution of the variable is approximately preserved, even though individual values may have changed.
PRAM: some categorical values (here gender) are randomly recoded to another category with a set probability.
This technique can be applied to the keyVars we defined in the sdcObject earlier, but does not improve k-anonymity indicators since it doesn’t reduce the amount of unique combinations but rather changes the accuracy of those combinations. It is therefore an additional level of protection that sdcMicro indicators can not measure.
Keeping Utility
After applying any perturbative technique, you should compare key statistics (means, standard deviations, correlations, regression coefficients) between the original and perturbed datasets. If the differences are small enough for your purposes, the perturbation has preserved utility. We cover formal utility measures in the chapter on balancing utility and privacy.
Pro and Contra of Using Perturbative Techniques
Pros:
No records or variables are removed; the dataset stays complete.
Statistical properties like means, variances, and correlations can be largely preserved
Easy to tune the privacy-utility trade-off by adjusting the noise level or group size.
Cons:
Individual values are no longer accurate. This makes perturbative techniques unsuitable if exact values matter—for example, if a researcher needs to verify that a specific participant had a specific income.
Risk of reverse-engineering: if the perturbation method and its parameters are known, an attacker may be able to approximately reconstruct the original values.
If applied too aggressively, perturbative techniques can distort subgroup statistics in ways that are hard to detect.
Exercise: Applying Perturbative Techniques
Let’s try out two common perturbative techniques: microaggregation and noise. Conveniently, both are available directly in sdcMicro.
Continue working with sdc_nonpert from the previous exercise.
Apply microaggregation (with the function microaggregation) to income using the default method ("mdav"). Start with a group size of aggr = 5.
Add additive noise to income (with the function adddNoise) as an alternative. Start with a noise parameter of 1 .
Compare the methods: Which parameters do you need to achieve similar levels of protection?
Tip
You cannot undo perturbation steps within the same sdcObject. Create a fresh copy of sdc_nonpert before trying the second method so you can compare them side-by-side.
ImportantSolution
Microaggregation
I start by applying microaggreagation with a group size of 5 on a new sdcObject.
# Microaggregation: replace income with group means (group size 5)sdc_micro <-microaggregation(obj = sdc_nonpert,variables ="income",aggr =5, # group sizemethod ="mdav"# Maximum Distance to Average Vector)sdc_micro
The input dataset consists of 200 rows and 12 variables.
--> Categorical key variables: gender, age, education, plz
--> Numerical key variables: income, years_in_job
----------------------------------------------------------------------
Information on categorical key variables:
Reported is the number, mean size and size of the smallest category >0 for recoded variables.
In parenthesis, the same statistics are shown for the unmodified data.
Note: NA (missings) are counted as seperate categories!
Key Variable Number of categories Mean size
<char> <char> <char> <char> <char>
gender 4 (3) 64.667 (66.667)
age 5 (52) 40.000 (3.846)
education 5 (5) 32.000 (40.000)
plz 3 (152) 99.000 (1.316)
Size of smallest (>0)
<char> <char>
4 (10)
23 (1)
5 (9)
90 (1)
Infos on 2/3-Anonymity:
Number of observations violating
- 2-anonymity: 0 (0.000%) | in original data: 198 (99.000%)
- 3-anonymity: 0 (0.000%) | in original data: 200 (100.000%)
- 5-anonymity: 29 (14.500%) | in original data: 200 (100.000%)
----------------------------------------------------------------------
Numerical key variables: income, years_in_job
Disclosure risk (~100.00% in original data):
modified data: [0.00%; 77.50%]
Current Information Loss in modified data (0.00% in original data):
IL1: 1029.80
Difference of Eigenvalues: 6.100%
----------------------------------------------------------------------
Risk measures:
Number of observations with higher risk than the main part of the data:
in modified data: 29
in original data: 0
Expected number of re-identifications:
in modified data: 30.27 (15.13 %)
in original data: 199.00 (99.50 %)
data_micro <-extractManipData(sdc_micro) # Extract the manipulated data
mdav groups records by their distance to the group centroid, then replaces each value with the group mean. With aggr = 5, at least 5 records share the same income value, so singling out an individual is harder.
As we can see in the output of the sdcObject, the disclosure risk is reduced from up to 100% in the beginning to a range going only up to 77.5%.
Additive noise
# Additive noise on incomesdc_noise <-addNoise(obj = sdc_nonpert,variables ="income",noise =3.5# noise level as fraction of SD)print(sdc_noise, type ="risk")
Risk measures:
Number of observations with higher risk than the main part of the data:
in modified data: 29
in original data: 0
Expected number of re-identifications:
in modified data: 30.27 (15.13 %)
in original data: 199.00 (99.50 %)
sdc_noise
The input dataset consists of 200 rows and 12 variables.
--> Categorical key variables: gender, age, education, plz
--> Numerical key variables: income, years_in_job
----------------------------------------------------------------------
Information on categorical key variables:
Reported is the number, mean size and size of the smallest category >0 for recoded variables.
In parenthesis, the same statistics are shown for the unmodified data.
Note: NA (missings) are counted as seperate categories!
Key Variable Number of categories Mean size
<char> <char> <char> <char> <char>
gender 4 (3) 64.667 (66.667)
age 5 (52) 40.000 (3.846)
education 5 (5) 32.000 (40.000)
plz 3 (152) 99.000 (1.316)
Size of smallest (>0)
<char> <char>
4 (10)
23 (1)
5 (9)
90 (1)
Infos on 2/3-Anonymity:
Number of observations violating
- 2-anonymity: 0 (0.000%) | in original data: 198 (99.000%)
- 3-anonymity: 0 (0.000%) | in original data: 200 (100.000%)
- 5-anonymity: 29 (14.500%) | in original data: 200 (100.000%)
----------------------------------------------------------------------
Numerical key variables: income, years_in_job
Disclosure risk (~100.00% in original data):
modified data: [0.00%; 77.50%]
Current Information Loss in modified data (0.00% in original data):
IL1: 880.05
Difference of Eigenvalues: 5.950%
----------------------------------------------------------------------
addNoise draws from a normal distribution with mean 0 and standard deviation = noise × sd(income) and adds it to each value. Every record gets a unique (slightly wrong) income. When noise = 3.5, we achieve a disclosure risk between 0% and 75.5%, instead of one between 0% and 100% that we started with.
# Save the perturbed sdcObjects for the balancing chaptersaveRDS(sdc_micro, here::here("sdc_micro.rds"))saveRDS(sdc_noise, here::here("sdc_noise.rds"))