4) Data Management Plans
Overview
As the previous sections have shown, data management is a broad topic encompassing various aspects. Hence, good planning is essential to effectively manage data according to the FAIR principles. Writing a (research) data management plan (DMP) is ideal to predefine how data will be handled. This part of the tutorial provides an overview of the components of a DMP, offers tips on creating one, and introduces helpful tools. It concludes with a practical exercise where you will work on a small section of a DMP.
General information
A data management plan is a written document describing the data you expect to collect or use during a research project. Further, a DMP shows how you will manage, describe, analyze, and store the data, as well as the mechanisms for sharing and preserving data when your project is complete. Thus, a data management plan accompanies and guides you throughout the project and encompasses all phases that research data go through in a project. Following the motto “start early, refine often”, creating a DMP at the beginning of your project enables it to be a living document that evolves alongside your research. Begin with basic information and enrich the document as your project progresses. Note that it is not required to answer all questions; stick to those relevant to your data. DMPs apply to any research project, from a PhD thesis to large collaborative research projects.
Components of a DMP
Throughout a project, there are different processing stages regarding data. You can illustrate the process as a life cycle with the following stages:
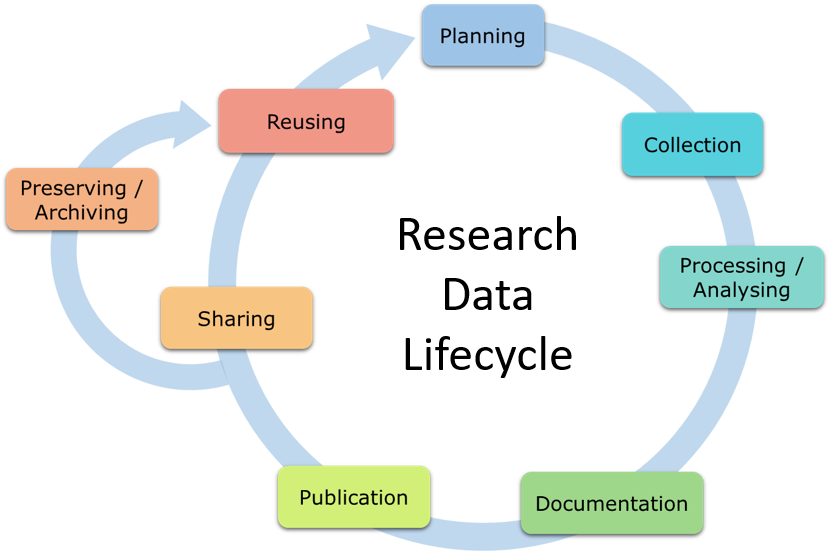
A data management plan covers all stages of the research data life cycle by assigning questions to each stage. Addressing the questions relevant to your research project will result in a comprehensive DMP. Exemplary questions include:
- What data will be collected, and where do they come from?
- Which metadata should be used to describe the data?
- Where should the data be stored? During the project phase? After the project?
- What about Open Data? Do you plan to publish the data?
- Does your project require personnel resources for data management? Does your project require special infrastructure?
- How do you ensure the quality of your data?
- Is your research project concerned with personal or sensitive data? What laws apply? Are there ethical aspects you need to consider?1
Please note that this list is incomplete, and the questions may vary depending on your discipline and data specifics.
Looking at published DMPs, especially from your discipline, may be helpful to gain a deeper insight into the topic. Have a look at the following list to find some example DMPs. (Note: some of these collections are not uptodate.)
- Argos Published DMPs
- Digital Curation Centre Example DMPs and Guidance
- Public DMPs by DMPonline
- LIBER Europe DMP Catalogue
- Examples for Horizon 2020 DMPs by the University of Vienna
- Data management plans in the RIOjournal
Example: Data storage and security
In this section, we approach a DMP from a practical perspective: In the following, we will look at one specific section of a DMP, namely “Data storage and security” and provide example answers for two datasets. Given that this is quite a relevant topic for data management that we have not yet covered in the previous sections, we start by providing some background information on data storage and security. (If you already feel comfortable with the topic, you can skip this part.)
Regarding data storage and security, the following three “S” encompass the topic: safe - secure - sustainable. Now, we dive into the main principles of each part:
Safe
Safety focuses on the protection of data against physical loss.2 To ensure your data’s safety and recoverability, establish a regular backup routine. This involves creating copies of your data at specified times and storing them separately from the originals, ideally adhering to the 3-2-1 rule (see below). Consider using external hard drives or USB sticks for local backups.3 Additionally, if your institution offers backup systems like LRZ cloud storage or LRZ Sync+Share, you can store your data where they have automated backup mechanisms. Another synched storage is Keeper, a service available for all Max Planck employees.
The 3-2-1 backup rule states that you should maintain three copies of your data on two different storage mediums (e.g. local storage and external hard drive), with one copy stored in a remote location. A remote copy can be stored in the cloud.
Remember, your backups should encompass your data files and include software applications if necessary. This ensures a comprehensive recovery if needed.4
Secure
Protecting data against unauthorized access and data misuse is one of the main goals of security.5 We recommend using access control mechanisms and encryption to prevent unauthorized access to data and to protect sensitive information. Confidential data is sensitive information that could cause harm if disclosed, such as details about endangered species, vulnerable archaeological sites, or personal information. Personal data is subject to strict privacy laws (cp. General Data Protection Regulations) and requires secure handling. To protect sensitive data, it is crucial to minimize the risk of identification through techniques like pseudonymization (i.e., replace personally identifiable information by a pseudonym) or anonymization (i.e., complete removal of personally identifiable information from the research data). Additionally, strong password protection using reliable password management tools is essential to prevent unauthorized access.6
Sustainable
Data sustainability aims at making data persistent across technological and human evolution.7 Concretely, this means choosing file formats that are unlikely to become obsolete and ensuring the long-term readability and accessibility of your data. For more details on this topic, revisit Part 3: Organization / File formats.
Example answers for a DMP
The following examples are intended to show how specific questions can be answered in a DMP. The questions are part of the RDMO template, section “Data usage / Data storage and security” and “Data usage / Interoperability”. For each question, we will provide you with example answers for two datasets. These answers do not rely on any existing project. Also, the data and some tools (e.g. software) are invented. The example answers are based on the information in this example DMP.
- Dataset “Simulations of neural signal transmission”: The simulations use the open-source “QuantumNeuroBrain” (made up) software suite. We determine potentials and signals for various environments. The simulations vary the environment parameters (ion concentrations, temperature, …) and consider eight different models for the transduction mechanism proposed in the literature (also not relying on actual literature research). The simulations themselves follow from input files (for models, parameters, etc.) and configuration files that capture the used settings in software and hardware. The simulation output is further analyzed and forms the basis for illustrative images. Input, configuration files, output and derived data, such as images, are intimately connected and are considered a single diverse dataset.
- Dataset “EEG measurements”: This dataset includes high-resolution EEG measurements from up to 100 probands. Additional measurements will accompany the EEG measurements to determine the environmental conditions (see previous dataset). The measurements will be performed using a Neuro++ machine (made up), allowing for state-of-the-art sensitivity. Existing measurements will supplement the dataset from a local neuroscience group. We use the open-source tool EEGalyse (made up) to analyze and visualize the results.
Safe:
- How and how often will backups of the data be created? (This question refers to backups while the data is being worked with only, not long-term preservation.)
- Dataset “Simulations of neural signal transmission”: While all data are initially stored on local servers in the research institute, all data that pass the initial quality checks are additionally transferred to servers of the university computing centre. Here, automatic backup services are available daily.
- Dataset “EEG measurements”: All data are stored on local servers in the research institute. The RAID system provides redundancy, and all data are backed up daily. Fully anonymized data are also stored on IT centre servers to add a layer of redundancy.
- Who is responsible for the backups? (This question refers to backups while the data is being worked with only, not long-term preservation.)
- Dataset “Simulations of neural signal transmission”: All project members themselves store their data on local servers in the research institute. If the data passes the initial quality checks, all researchers transfer their data to the university computing centre.
- Dataset “EEG measurements”: All project members themselves store their data on local servers in the research institute. The backup is then done automatically. Furthermore, the research data manager transfers the fully anonymized data to the IT centre.
Secure:
- Who is allowed to access the dataset (e.g., project members, partners of the project, only in-house, external partners)?
- Dataset “Simulations of neural signal transmission”: Only project members are allowed to access the data.
- Dataset “EEG measurements”: Only persons who are part of the EEG group of the project team are allowed to access the sensitive data. All folders are, therefore, password-protected. A detailed list of the persons who can access the data are stored in the project filesystem. Once the data is anonymized, the research manager transfers it to the IT centre, where the IT centre staff and all project members can access the data.
- Which measures or provisions are in place to ensure data security (e.g. protection against unauthorized access, data recovery, transfer of sensitive data)?
- Dataset “Simulations of neural signal transmission”:
- Protection against unauthorized access: Detailed access and rights management via the university identity management (IdM) system
- Data recovery - backups: Automated backups to university computing centre servers
- Dataset “EEG measurements”:
- Protection against unauthorized access: Detailed access and rights management via the university IdM system, additional password protection of sensitive data
- Data robustness - encryption: Transfer of data between systems only in encrypted form (AES encrpytion)
- Data recovery - backups: Each encrypted and fully anonymized dataset is backed up by IT centre servers. The local secure RAID system provides redundancy for sensitive data during all stages of data handling.
- Sensitive data - anonymization or pseudonymization: Access to sensitive (not fully anonymous) data is only possible for the EEG group members and on a computer physically located in the rooms of the research group.
- Other: The research data manager will ensure that all group members are comfortable with the established data handling procedures, particularly regarding sensitive information, as well as using the backup service and documentation of all data handling and versioning steps.
Sustainable:
Is this dataset interoperable, e.g. allowing data exchange and reuse between researchers, institutions, organizations, countries, etc.? (Note that this question covers a broader scope than just sustainability.)
Dataset “Simulations of neural signal transmission”:
Dataset “EEG measurements”:
Why is a DMP helpful?
Creating a DMP may seem like (and certainly is) a lot of work, but it comes with numerous benefits for you and your research:
- Enhanced organization: A DMP forces you to think through important aspects before your project actually starts, ensuring that your data is well-documented, organized, and easily accessible throughout the project.
- One living document: It contains all information regarding data management for your project, so you can always go back, look things up, make changes or additions but you can also pass it on to e.g. new project members instead of explaining the same things over and over.
- Improved reproducibility: Thorough documentation promotes transparency and facilitates replication of your research findings.
- Efficient data sharing: A DMP helps considering important aspects for data publication (e.g., having participants’ consent) and therefore simplifies data sharing once the project ends.
As mentioned, a DMP addresses crucial technical, organizational, legal, and financial considerations for your project right from the beginning and provides a comprehensive overview of all potential data management tasks. It structures your workflow and builds the basis for optimizations. Also, a DMP supports your own good scientific work by ensuring your data is complete, accurate and trustworthy.
Furthermore, a data management plan can be part of applications and reports to third-party-funded projects. When applying for grants, submitting a DMP may be mandatory (see Excursion: Funder requirements). Beyond that, more and more institutions adopt guidelines for handling research data. You can find an overview of universities in Bavaria with a research data policy here.
In conclusion, a DMP is a helpful tool that streamlines your workflow and supports you in fostering research integrity.
Many funding agencies ask for information on handling research data. The following table8 provides an overview of the requirements of German and European funding agencies:
| Funder | DMP demanded? | Submission on application? | Content | Updates? |
|---|---|---|---|---|
| European Commission, Horizon Europe | Yes | Comprehensive plan within the first 6 month of the project | Horizon Europe DMP template; Information and template for ERC grants | Update, if significant changes occur and at the end of the project |
| German Research Foundation (DFG) | Information on the handling of research data | Yes | Contents of the DFG Guidelines on the Handling of Research Data | No |
| German Federal Ministry of Education and Research (BMBF) | Plan sometimes required, depending on the programme | If required, yes | Content depends on the respective programme; Educational research: Checklist (in German) | Depends on the programme |
| Volkswagen Stiftung (VW Foundation) | Yes | Yes | Template for a Base-DMP | No |
DMP tool: RDMO
Different software is available to streamline the DMP creation process, simplify workflows, and empower collaborative work.
It is essential to clarify the difference between a DMP tool and a repository: A DMP tool is a planning tool where you gather information about research data management in general, e.g. about data collection, description, etc. You can also use it as a documentation tool but it does not store your actual research data. A repository in contrast is a platform where you eventually store and publish your data.
One of these tools is the Research Data Management Organiser (RDMO). RDMO is an open-source online tool designed to create, store and print your DMP. It supports you in planning projects and administrating data management tasks throughout the whole data life cycle. The tool is an outcome of a project co-funded by the German Research Foundation (DFG) between 2015 and 2020 and is constantly developed and optimized. The University Library of LMU Munich and the Max Planck Digital Library offer instances of the web-based software on their servers (which means both institutions offer their “own” RDMO application). You can register using your email or ORCID for LMU RDMO or your MPG login (Shibboleth) for MPG RDMO.
Key features of RDMO:
- Templates and guidance: To create a DMP (called a project in RDMO), choose one of the pre-built templates that are designed as questionnaires. The questions highlight the aspects we discussed earlier and guide you step-by-step through the creation process. Some questionnaires are based on the requirements of different research funding agencies, e.g., the German Research Foundation (DFG).
- Collaboration-friendly: It is possible to work collaboratively on one DMP as a team. Therefore, RDMO supports different roles for the project members: visitor, author, manager and owner. The owner can edit and delete the project, whereas a visitor has read-only rights.
- Import and export: Furthermore, RDMO offers import and export features. A DMP can be exported to formats like PDF, XML, or Markdown. The exported document provides a good guide for internal documentation and could be a suitable tool for reporting to the funding agency.
- Version control: RDMO stores only the current version of a DMP, but the “Snapshot” feature allows you to manually track changes and revert to previous versions, giving you full control over your data management plan.
Further information on the features of RDMO can be found here: RDMO Quick Start Guide by University Library of LMU Munich (Download, PDF) and Quick Start to RDMO for MPG.
In addition to RDMO, a variety of DMP tools exist. The following table9 provides an overview of discipline-agnostic DMP tools that are freely available online:
| Name | Provider | Templates | |
|---|---|---|---|
| ARGOS | OpenAIRE, EUDAT | CHIST-ERA | |
| DMPonline | Digital Curation Center (DCC) | European programs (e.g. Horizon Europe), funding agencies from different European countries, mainly the UK; DDC template | |
| DMPTool | University of California, California Digital Library | mostly US funding agencies; DCC template | |
| Data Stewardship Wizard | ELIXIR CZ / ELIXIR NL | Horizon Europe, Science Europe, maDMP | |
| GFBio DMPT | GFBio | - |
If you do not yet have a RDMO account, please register now. Either use the LMU RDMO (register using your email or ORCID id) or MPG RDMO (MPG login: Shibboleth). Login and create a new project using the RDMO catalog.
Answer the questions for a subset of the following sections for the dataset you previously worked on:
- Content classification / Datasets
- Content classification / Re-use
- Technical classification / Formats
- Data usage / Data organization
- Data usage / Data sharing and re-use
- Metadata and referencing / Metadata
You can summarize the outcome of the previous tasks and discuss your thoughts with your group members.
We do not provide a solution for this task as it summarizes the previous tasks. Also, note that there is no correct DMP. Try to be as precise as possible and provide detailed information on your project and research data. Depending on your data and discipline, some questions may be obsolete and do not need to be answered.
Footnotes
Questions based on: https://www.fdm.uni-hamburg.de/fdm/datenmanagementplan.html↩︎
based on: https://www.baramundi.com/de-de/blog/artikel/unterschied-safety-security/↩︎
based on: https://www.forschungsdaten.info/themen/speichern-und-rechnen/datensicherheit-und-backup/↩︎
based on: https://www.forschungsdaten.info/themen/speichern-und-rechnen/datensicherheit-und-backup/↩︎
based on: https://www.baramundi.com/de-de/blog/artikel/unterschied-safety-security/↩︎
based on: https://doi.org/10.17605/OSF.IO/GDQ93 and https://www.forschungsdaten.info/themen/speichern-und-rechnen/datensicherheit-und-backup/↩︎
based on: https://doi.org/10.1016/j.infoandorg.2023.100449↩︎
based on: https://doi.org/10.5281/zenodo.5773203↩︎
based on: https://forschungsdaten.info/themen/informieren-und-planen/datenmanagementplan/.↩︎